Preference fine-tuning allows you to train models using pairs of preferred and non-preferred examples. This approach is more effective than standard fine-tuning when you have paired examples that show which responses your model should generate and which it should avoid. We use Direct Preference Optimization (DPO) for this type of fine-tuning. Before proceeding: Review our How-to: Fine-tuning guide for an overview of the fine-tuning process.Documentation Index
Fetch the complete documentation index at: https://togetherai-migration.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Data Preparation
Your dataset should contain examples with:- An
inputfield with messages in in the conversational format. - A
preferred_outputfield with the ideal assistant response - A
non_preferred_outputfield with a suboptimal assistant response
JSONL, with each line structured as:
Preference-tuning does not support pretokenized datasets. Contact us if you need to use them for preference training.
Launching preference fine-tuning
Hyperparameters
-
Set
--training-method="dpo" -
The
--dpo-betaparameter controls how much the model is allowed to deviate from its reference (or pre-tuned) model during fine-tuning. The default value is0.1but you can experiment with values between0.05-0.9- A lower value of beta (e.g., 0.1) allows the model to update more aggressively toward preferred responses
- A higher value of beta(e.g., 0.7) keeps the updated model closer to the reference behavior.
Note
- For LoRA Long-context fine-tuning we currently use half of the context length for the preferred response and half for the non-preferred response. So, if you are using a 32K model, the effective context length will be 16K.
- Preference fine-tuning calculates loss based on the preferred and non-preferred outputs. Therefore, the
--train-on-inputsflag is ignored with preference fine-tuning.
Metrics
In addition to standard metrics like losses, for DPO we report:- Accuracies — percentage of times the reward for the preferred response is greater than the reward for the non-preferred response.
- KL Divergence — similarity of output distributions between the trained model and the reference model, calculated as:
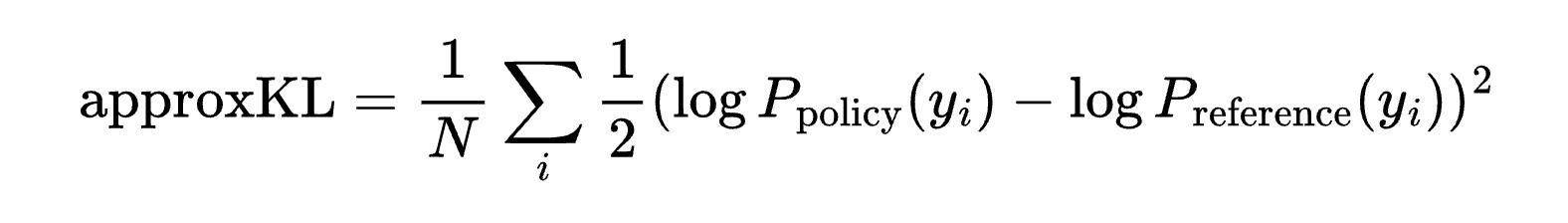
Combining methods: supervised fine-tuning & preference fine-tuning
Supervised fine-tuning (SFT) is the default method on our platform. The recommended approach is to first perform SFT followed up by preference tuning as follows:- First perform supervised fine-tuning (SFT) on your data.
- Then refine with preference fine-tuning using continued fine-tuning on your SFT checkpoint.